The Gini coefficient measures the inequality among values of a frequency distribution (for example levels of income). A Gini coefficient of zero expresses perfect equality where all values are the same (for example, where everyone has an exactly equal income). A Gini coefficient of one (100 on the percentile scale) expresses maximal inequality among values (for example where only one person has all the income).[3]
It has found application in the study of inequalities in disciplines as diverse as sociology, economics, health science, ecology, chemistry, engineering and agriculture.[4] It is commonly used as a measure of inequality of income or wealth.[5] Worldwide, Gini coefficients for income range from approximately 0.23 (Sweden) to 0.70 (Namibia) although not every country has been assessed.
Contents[hide] |
[edit] Definition

The graph shows that the Gini is equal to the area marked 'A' divided by the sum of the areas marked 'A' and 'B' (that is, Gini = A/(A+B)). It is also equal to 2*A, as A+B = 0.5 (since the axes scale from 0 to 1).
The Gini coefficient can range from 0 to 1; it is sometimes expressed as a percentage ranging between 0 and 100. More specifically, the upper bound of the Gini coefficient equals 1 only in populations of infinite size. In a population of size N, the upper bound is equal to 1 − 2 / (N + 1).
A low Gini coefficient indicates a more equal distribution, with 0 corresponding to complete equality, while higher Gini coefficients indicate more unequal distribution, with 1 corresponding to complete inequality. To be validly computed, no negative goods can be distributed. Thus, if the Gini coefficient is being used to describe household income inequality, then no household can have a negative income. When used as a measure of income inequality, the most unequal society will be one in which a single person receives 100% of the total income and the remaining people receive none (G=1); and the most equal society will be one in which every person receives the same income (G=0).
An alternative approach would be to consider the Gini coefficient as half of the relative mean difference, which is a mathematical equivalence. The mean difference is the average absolute difference between two items selected randomly from a population, and the relative mean difference is the mean difference divided by the average, to normalize for scale.
[edit] Calculation
The Gini index is defined as a ratio of the areas on the Lorenz curve diagram. If the area between the line of perfect equality and the Lorenz curve is A, and the area under the Lorenz curve is B, then the Gini index is A/(A+B). Since A+B = 0.5, the Gini index, G = A/(0.5) = 2A = 1-2B. If the Lorenz curve is represented by the function Y = L(X), the value of B can be found with integration and:
- For a population uniform on the values yi, i = 1 to n, indexed in non-decreasing order ( yi ≤ yi+1):

- This may be simplified to:

- For a discrete probability function f(y), where yi, i = 1 to n, are the points with nonzero probabilities and which are indexed in increasing order ( yi < yi+1):

- where
 and
and 
- For a cumulative distribution function F(y) that is piecewise differentiable, has a mean μ, and is zero for all negative values of y:

- Since the Gini coefficient is half the relative mean difference, it can also be calculated using formulas for the relative mean difference. For a random sample S consisting of values yi, i = 1 to n, that are indexed in non-decreasing order ( yi ≤ yi+1), the statistic:

- is a consistent estimator of the population Gini coefficient, but is not, in general, unbiased. Like G, G(S) has a simpler form:
 .
.
For some functional forms, the Gini index can be calculated explicitly. For example, if y follows a lognormal distribution with the standard deviation of logs equal to σ, then
 where Φ() is the cumulative distribution function of the standard normal distribution.
where Φ() is the cumulative distribution function of the standard normal distribution.Sometimes the entire Lorenz curve is not known, and only values at certain intervals are given. In that case, the Gini coefficient can be approximated by using various techniques for interpolating the missing values of the Lorenz curve. If ( X k, Yk ) are the known points on the Lorenz curve, with the X k indexed in increasing order ( X k - 1 < X k ), so that:
- Xk is the cumulated proportion of the population variable, for k = 0,...,n, with X0 = 0, Xn = 1.
- Yk is the cumulated proportion of the income variable, for k = 0,...,n, with Y0 = 0, Yn = 1.
- Yk should be indexed in non-decreasing order (Yk>Yk-1)

The Gini coefficient calculated from a sample is a statistic and its standard error, or confidence intervals for the population Gini coefficient, should be reported. These can be calculated using bootstrap techniques but those proposed have been mathematically complicated and computationally onerous even in an era of fast computers. Ogwang (2000) made the process more efficient by setting up a “trick regression model” in which the incomes in the sample are ranked with the lowest income being allocated rank 1. The model then expresses the rank (dependent variable) as the sum of a constant A and a normal error term whose variance is inversely proportional to yk;

However it has since been argued that this is dependent on the model’s assumptions about the error distributions (Ogwang 2004) and the independence of error terms (Reza & Gastwirth 2006) and that these assumptions are often not valid for real data sets. It may therefore be better to stick with jackknife methods such as those proposed by Yitzhaki (1991) and Karagiannis and Kovacevic (2000). The debate continues.
The Gini coefficient can be calculated if you know the mean of a distribution, the number of people (or percentiles), and the income of each person (or percentile). Princeton development economist Angus Deaton (1997, 139) simplified the Gini calculation to one easy formula:
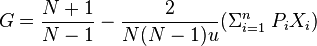
[edit] Generalised inequality index
See also: Generalized entropy index
The Gini coefficient and other standard inequality indices reduce to a
common form. Perfect equality—the absence of inequality—exists when and
only when the inequality ratio,  , equals 1 for all j units in some population; for example, there is perfect income equality when everyone’s income xj equals the mean income
, equals 1 for all j units in some population; for example, there is perfect income equality when everyone’s income xj equals the mean income  , so that rj = 1 for everyone). Measures of inequality, then, are measures of the average deviations of the rj = 1
from 1; the greater the average deviation, the greater the inequality.
Based on these observations the inequality indices have this common
form:[6]
, so that rj = 1 for everyone). Measures of inequality, then, are measures of the average deviations of the rj = 1
from 1; the greater the average deviation, the greater the inequality.
Based on these observations the inequality indices have this common
form:[6]
[edit] Gini coefficient of income distributions
See also: List of countries by income equality
While developed European nations and Canada
tend to have Gini indices between 0.24 and 0.36, the United States' and
Mexico's Gini indices are both above 0.40, indicating that the United States (according to the US Census Bureau[7][8][9]) and Mexico have greater inequality. Using the Gini can help quantify differences in welfare and compensation
policies and philosophies. However it should be borne in mind that the
Gini coefficient can be misleading when used to make political
comparisons between large and small countries (see criticisms section).The Gini index for the entire world has been estimated by various parties to be between 0.56 and 0.66.[10][11] The graph shows the values expressed as a percentage, in their historical development for a number of countries.

[edit] EU Gini index
In 2005 the Gini index for the EU was estimated at 31.[12][edit] US income Gini indices over time
Gini indices for the United States at various times, according to the US Census Bureau:[13][14][15]- 1929: 45.0 (estimated)
- 1947: 37.6 (estimated)
- 1967: 39.7 (first year reported)
- 1968: 38.6 (lowest index reported)
- 1970: 39.4
- 1980: 40.3
- 1990: 42.8
- 2000: 46.2
- 2005: 46.9
- 2006: 47.0 (highest index reported)
- 2007: 46.3
- 2008: 46.69
- 2009: 46.8
[edit] Advantages and disadvantages
|
|
This section contains a pro and con list. Please help improve it by integrating both sides into a more neutral presentation. (February 2011) |
|
|
This section may contain original research. Please improve it by verifying the claims made and adding references. Statements consisting only of original research may be removed. More details may be available on the talk page. (December 2010) |
[edit] Advantages of Gini coefficient as a measure of inequality
The Gini coefficient's main advantage is that it is a measure of inequality by means of a ratio analysis. This makes it easily interpretable, and avoids references to a statistical average or position unrepresentative of most of the population, such as per capita income or gross domestic product. The simplicity of Gini makes it easy to use for comparison across diverse countries and also allows comparison of income distributions across different groups as well as countries; for example the Gini coefficient for urban areas differs from that of rural areas in many countries (though not in the United States). Like any time-based measure, Gini coefficients can be used to compare income distribution over time, thus it is possible to see if inequality is increasing or decreasing independent of absolute incomes. The Gini coefficient satisfies four principles suggested to be important:[16]- Anonymity: it does not matter who the high and low earners are.
- Scale independence: the Gini coefficient does not consider the size of the economy, the way it is measured, or whether it is a rich or poor country on average.
- Population independence: it does not matter how large the population of the country is.
- Transfer principle: if income (less than the difference), is transferred from a rich person to a poor person the resulting distribution is more equal.
[edit] Disadvantages of Gini coefficient as a measure of inequality
The limitations of Gini largely lie in its relative nature: It loses information about absolute national and personal incomes. Countries may have identical Gini coefficients, but differ greatly in wealth. Basic necessities may be equal (available to all) in a rich country, while in the poor country, even basic necessities are unequally available.By measuring inequality in income, the Gini ignores the differential efficiency of use of household income. By ignoring wealth (except as it contributes to income) the Gini can create the appearance of inequality when the people compared are at different stages in their life. Wealthy countries (e.g. Sweden) can appear more equal, yet have high Gini coefficients for wealth (for instance 77% of the share value owned by households is held by just 5% of Swedish shareholding households).[17][dead link] These factors are not assessed in income-based Gini.
Gini has some mathematical limitations as well. For instance, different sets of people cannot be averaged to obtain the Gini coefficient of all the people in the sets: if a Gini coefficient were to be calculated for each person it would always be zero. For a large, economically diverse country, a much higher coefficient will be calculated for the country as a whole than will be calculated for each of its regions. (The coefficient is usually applied to measurable nominal income rather than local purchasing power, tending to increase the calculated coefficient across larger areas.)
As is the case for any single measure of a distribution, economies with similar incomes and Gini coefficients can still have very different income distributions. This results from differing shapes of the Lorenz curve. For example, consider a society where half of individuals had no income and the other half shared all the income equally (i.e. whose Lorenz curve is linear from (0,0) to (0.5,0) and then linear to (1,1)). As is easily calculated, this society has Gini coefficient 0.5 -- the same as that of a society in which 75% of people equally shared 25% of income while the remaining 25% equally shared 75% (i.e. whose Lorenz curve is linear from (0,0) to (0.75,0.25) and then linear to (1,1)).
Too often only the Gini coefficient is quoted without describing the proportions of the quantiles used for measurement. As with other inequality coefficients, the Gini coefficient is influenced by the granularity of the measurements. For example, five 20% quantiles (low granularity) will usually yield a lower Gini coefficient than twenty 5% quantiles (high granularity) taken from the same distribution. This is an often encountered problem with measurements.
Care should be taken in using the Gini coefficient as a measure of egalitarianism, as it is properly a measure of income dispersion. For example, if two equally egalitarian countries pursue different immigration policies, the country accepting a higher proportion of low-income or impoverished migrants will be assessed as less equal (gain a higher Gini coefficient).
Expanding on the importance of life-span measures, the Gini coefficient as a point-estimate of equality at a certain time, ignores life-span changes in income. Typically, increases in the proportion of young or old members of a society will drive apparent changes in equality, simply because people generally have lower incomes and wealth when they are young than when they are old. Because of this, factors such as age distribution within a population and mobility within income classes can create the appearance of differential equality when none exist taking into account demographic effects. Thus a given economy may have a higher Gini coefficient at any one point in time compared to another, while the Gini coefficient calculated over individuals' lifetime income is actually lower than the apparently more equal (at a given point in time) economy's.[18] Essentially, what matters is not just inequality in any particular year, but the composition of the distribution over time.
[edit] General problems of measurement
- Comparing income distributions among countries may be difficult because benefits systems may differ. For example, some countries give benefits in the form of money while others give food stamps, which might not be counted by some economists and researchers as income in the Lorenz curve and therefore not taken into account in the Gini coefficient. The Soviet Union was measured to have relatively high income inequality: by some estimates, in the late 1970s, Gini coefficient of its urban population was as high as 0.38,[19] which is higher than many Western countries today. This number would not reflect those benefits received by Soviet citizens that were not monetized for measurement, which may include child care for children as young as two months, elementary, secondary and higher education, cradle-to-grave medical care, and heavily subsidized or provided housing. In this example, a more accurate comparison between the 1970s Soviet Union and Western countries may require one to assign monetary values to all benefits – a difficult task in the absence of free markets. Similar problems arise whenever a comparison between more liberalized economies and partially socialist economies is attempted. Benefits may take various and unexpected forms: for example, major oil producers such as Venezuela and Iran provide indirect benefits to its citizens by subsidizing the retail price of gasoline.
- Similarly, in some societies people may have significant income in other forms than money, for example through subsistence farming or bartering. Like non-monetary benefits, the value of these incomes is difficult to quantify. Different quantifications of these incomes will yield different Gini coefficients.
- The measure will give different results when applied to individuals instead of households. When different populations are not measured with consistent definitions, comparison is not meaningful.
- As for all statistics, there may be systematic and random errors in the data. The meaning of the Gini coefficient decreases as the data become less accurate. Also, countries may collect data differently, making it difficult to compare statistics between countries.
[edit] Credit risk
The Gini coefficient is also commonly used for the measurement of the discriminatory power of rating systems in credit risk management.The discriminatory power refers to a credit risk model's ability to differentiate between defaulting and non-defaulting clients. The above formula G1 may be used for the final model and also at individual model factor level, to quantify the discriminatory power of individual factors. This is as a result of too many non defaulting clients falling into the lower points scale e.g. factor has a 10 point scale and 30% of non defaulting clients are being assigned the lowest points available e.g. 0 or negative points. This indicates that the factor is behaving in a counter-intuitive manner and would require further investigation at the model development stage.[20]
